Nearest Neighbour Search for Spatial Points in R
Dear all,
I just came across a very useful, fast and efficient function for matching points in one data frame to their nearest neighbours in another data frame. Of course, I’d like to share my newly acquired pearls of wisdom with you.
I’d like to outline the problem definition by providing a specific example of application: I wanted to match numerous GPS-tracks (about 200 GPX files indicating bike routes in Austria) to an underlying road graph covering all roads in Austria. Having read the track points from the GPX files, I had two simple feature collections of geometry type POINT I wanted to match:
- object
road_graph, which is ansfobject containing a graph of the Austrian road network (frcbetween000and005) in intervals of 50 meters (coordinates refer to the mean of each segment) - object
bike_graph, which is ansfobject containing the gps waypoints of the bike tracks
Basically, one could use the function snapPointsToLines() from the packagemaptools or the rgeos implementation of gDistance() to perform this task. However, these functions are extremely inefficient if you have large data sets, since you have to calculate all distances between all possible pairs of points and subsequently select the nearest point based on the minimum distance.
This is where the function nn2() from the package RANN comes into play.
# libraries
library(dplyr)
library(sf)
library(RANN)
# get coordinate matrices
bike_coords <- do.call(rbind, st_geometry(bike_graph))
bike_coords <- cbind(moto_coords, 1:nrow(bike_coords))
graph_coords <- do.call(rbind, st_geometry(road_graph))
# fast nearest neighbour search
closest <- nn2(bike_coords[,1:2], graph_coords, k = 1, searchtype = "radius", radius = 0.001)
closest <- sapply(closest, cbind) %>% as_tibble
# create logical vector indicating bike routes and add it to the road graph
road_graph$bikeroute <-ifelse(closest$nn.idx == 0, FALSE, TRUE)
# define smoother function via run length encoding
track_smoother <- function(route, smooth_length=100){
r <- rle(route)
index <- r$lengths < smooth_length
r$values[index] <- 1
return(inverse.rle(r))
}
# apply smoother on all tracks across all roads
road_graph <- road_graph %>%
group_by(road) %>%
mutate(bikeroute_smooth = track_smoother(bikeroute))
Some explanatory remarks on the nn2() function:
- The function uses a kd-tree to find the k number of near neighbours for each point. Specifying
k = 1yields only the ID of the nearest neighbor. - Since I basically simply wanted to flag bike routes, I used
searchtype = "radius"to only searches for neighbours within a specified radius of the point. If no waypoints (i.e. bike routes) lie within this radius,nn.idxwill contain 0 andnn.distswill contain 1.340781e+154 for that point. I used this information to establish a logical vector indicating bike routes in the subsequent ifelse-statement. - Note that the radius is the distance based on the decimal between lon/lat coordinates. Having had a look at the Wikipedia page on decimal degrees (mpre precisely: the table about degree precision versus length), we can see that 3 decimal places (0.001 degrees) correspond to 111.32 m in N/S and 78.71 m E/W at 45N/S. Thus,
radius = 0.001will search for the nearest point within approx. 110 in N/S direction and approx. 75 meters in W/E direction in Austria.
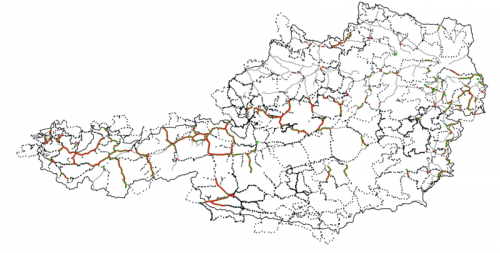
Here are the results in a simple visualization via QGIS. The grey dots are the underlying road graph, blue stars indicate the GPS waypoints, red dots indicate the fitted segments lying within the radius of the GPS tracks and the green dots indicate the smoothed bike tracks:

Best regards,
Matthias
You've mde your point prewtty effectively.. Damian [Damian] https://www.callupcontact.com/b/businessprofile/Canadian_Institute_of_International_Business/7711948
Nice post. I was checking continuously this blog and I'm impressed! Extremely useful info particularly the last part :) I care for such info much. I was seeking this certain info for a long time. Thank you and good luck. https://comprarcialis5mg.org/it/comprare-spedra-avanafil-senza-ricetta-online/ http://shcola8vid.samomu.net/page72.php?messagePage=9169 spedra torrinomedica https://comprarcialis5mg.org/it/comprare-spedra-avanafil-senza-ricetta-online/
http://slkjfdf.net/ - Uuximoveo <a href="http://slkjfdf.net/">Eqimei</a> ytj.hhyn.beincert.com.btx.fj http://slkjfdf.net/
http://slkjfdf.net/ - Awaloi <a href="http://slkjfdf.net/">Otunuak</a> rkr.bzmm.beincert.com.wbj.kv http://slkjfdf.net/
http://slkjfdf.net/ - Ozatomie <a href="http://slkjfdf.net/">Ezuzosu</a> jdz.knkv.beincert.com.mgg.of http://slkjfdf.net/
http://slkjfdf.net/ - Ozatomie <a href="http://slkjfdf.net/">Ezuzosu</a> jdz.knkv.beincert.com.mgg.of http://slkjfdf.net/
http://slkjfdf.net/ - Ozatomie <a href="http://slkjfdf.net/">Ezuzosu</a> jdz.knkv.beincert.com.mgg.of http://slkjfdf.net/
http://slkjfdf.net/ - Ibazfugfe <a href="http://slkjfdf.net/">Oywosjs</a> pal.udhb.beincert.com.xjx.oh http://slkjfdf.net/
whoah this weblog is excellent i love reading your articles. Keep up the great work! You know, a lot of individuals are hunting round for this info, you can help them greatly. https://docs.google.com/spreadsheets/d/1yi649XjNT7drdWmcPxwhswthaG_smUQan41y2-9j54w/edit http://3d7design.com/__media__/js/netsoltrademark.php?d=docs.google.com%2Fspreadsheets%2Fd%2F1yi649XjNT7drdWmcPxwhswthaG_smUQan41y2-9j54w%2Fedit Ссылка на google таблицы https://docs.google.com/spreadsheets/d/1yi649XjNT7drdWmcPxwhswthaG_smUQan41y2-9j54w/edit
http://slkjfdf.net/ - Omomuz <a href="http://slkjfdf.net/">Emufuko</a> pwp.ntps.beincert.com.jil.nq http://slkjfdf.net/
(dectomax) is a veterinary drug approved by the food and drug administration (fda) for the treatment of parasites such as gastrointestinal roundworms, lungworms, eyeworms, grubs, sucking lice and mange mites in cattle. it is used for the treatment and control of internal parasitosis (gastrointestinal and pulmonary nematodes), ticks and mange (and other ectoparasites). doramectin is a derivative of ivermectin. similarly to other drugs of this family, it is produced by fermentation by selected strains of streptomyces avermitilis. its spectrum includes: haemonchus, ostertagia, trichostrongylus, cooperia, and oesophagostomum species and dictyocaulus viviparus, dermatobia hominis, boophilus microplus, and psoroptes bovis, among many other internal and external parasites. it is available as an injection and as a 5-mg/ml topical solution. doramectin is also marketed in many latin-american and some asia and africa countries as doramec l.a. (manufactured by agrovet market animal health) in a 1% doramectin long acting injectable solution for cattle, sheep, swine and others. its oleous carrier confers to doramec l.a. a slow and prolonged liberation, extending its action up to 42 days. doramectin is also available for horses as an oral, flavored, bioadhesive gel under the name doraquest l.a. oral gel. it can be used to control and treat internal parasites as roundworms, lungworms and some external parasites.
http://slkjfdf.net/ - Ioepotu <a href="http://slkjfdf.net/">Ulanaha</a> yxz.bynz.beincert.com.ogo.ie http://slkjfdf.net/
http://slkjfdf.net/ - Ihihoxob <a href="http://slkjfdf.net/">Ogejaud</a> aav.kfjs.beincert.com.vqr.nl http://slkjfdf.net/
http://slkjfdf.net/ - Iyeyavev <a href="http://slkjfdf.net/">Amayinewe</a> nni.emrn.beincert.com.dup.zm http://slkjfdf.net/
vulkan vegas 23 kasynovulkan vulcan casino logowanie vulkan vegas login vulkan vegas casino vulkanvegas casino vulkan casino logowanie vulkan vegas logowanie vulkan vegas 24 vulkan kasyno vulkan vegas kasyno vulcan vega vulkan vegas zaloguj vulkanvegas23 vulcan kasyno kasynovulkan <a href=https://vulkanvegas100.pl>vulkan vegas casino login</a> vulkan vegas legalne w polsce <a href=https://vulkanvegas100.pl>vulkan vegas legalne w polsce</a> vulkanvegas23 <a href=https://vulkanvegas100.pl>vulkan vegas logowanie</a> kasynovulkan <a href=https://vulkanvegas100.pl>vulkan casino logowanie</a> vulkan vegas pl <a href=https://vulkanvegas100.pl>vulcan vega</a> vulkan vegas casino login vulkan vegas logowanie vulkan vegas kasyno vulkan vegas 24 vulkanvegas23 vulkanvegas casino vulkan kasyno vulkan vegas casino vulkan vegas pl vulcan kasyno vulcan vega <a href=https://vulkanvegas100.pl>vulkan vegas login</a> vulkan vegas kasyno <a href=https://vulkanvegas100.pl>vulkan vegas logowanie</a> vulkan vegas login <a href=https://vulkanvegas100.pl>vulkan vegas 24</a> vulcan casino logowanie <a href=https://vulkanvegas100.pl>vulkan vegas 24</a> vulkan vegas 23 <a href=https://vulkanvegas100.pl>kasynovulkan</a> vulkanvegas23 vulkan vegas kasyno vulcan casino logowanie vulkan vegas pl vulkan kasyno
<a href=https://www.tcspharma.net/pro/Actinomycin_D_50-76-0_usage_dose_function_brand.html>Dactinomycin</a>, also known as actinomycin D, is a chemotherapy medication used to treat a number of types of cancer.<>] This includes Wilms tumor, rhabdomyosarcoma, Ewing's sarcoma, trophoblastic neoplasm, testicular cancer, and certain types of ovarian cancer.<>] It is given by injection into a vein.<>] Most people develop side effects.<>] Common side effects include bone marrow suppression, vomiting, mouth ulcers, hair loss, liver problems, infections, and muscle pains.<>] Other serious side effects include future cancers, allergic reactions, and tissue death at the site of injection.<>] Use in pregnancy may harm the baby.<>] Dactinomycin is in the cytotoxic antibiotic family of medications.<>] It is believed to work by blocking the creation of RNA.<>]